How AI Search Actually Works
No jargon. No fluff. Just clear analogies that make LLMs, RAG, and AI search click for everyone.
No jargon. No fluff. Just clear analogies that make LLMs, RAG, and AI search click for everyone.
2025 was the year AI went mainstream. Here's the landscape everyone's building on.
And many more smaller releases, forks, and variants
Website traffic is dropping — but the demand for clear, discoverable content has never been higher.
MiniMax-Text-01 launches with 456B parameters
GPT-4.5 & early o-series models improve speed and reasoning
Gemini 2.0 goes multimodal across text, image, code, audio & video
Claude 4 Opus & Sonnet debut with deep reasoning and agent workflows
Gemini 2.5 Pro arrives with 1M token context window
Llama 4 Scout ships with 10M token context — largest ever
Qwen 3 becomes the most popular open-weight model
Grok 5 launches — strong in maths, coding, and reasoning
GPT-5 arrives: unified multimodal system with 400K token context
DeepSeek V3 hits 671B params — top open-source benchmark scores
Gemini 3 pushes further into advanced reasoning and tool use
The takeaway: Open-source models matched or beat proprietary systems on key benchmarks. The playing field levelled — and content structure became the differentiator, not budget.
From training to generation — the complete picture in plain English.
Imagine teaching someone to become a universal expert. They read the world's biggest library — every book, article, and forum. But instead of memorising word-for-word, they build a massive mind map of how ideas connect.
Billions of pages of text scraped from books, articles, forums, and code.
Text gets chopped into units the model can process — words, parts of words, punctuation.
A 3D web of connections is built — not storing facts, but patterns between ideas.
Training ends, the brain is frozen. Yesterday's news? The LLM doesn't know about it.
Think of it like your Spotify algorithm — but for all human knowledge. It doesn't store the songs, it stores the patterns of what goes together.
“Which Sydney firms handle antitrust for the technology industry?”
“[City] firms that handle antitrust for the technology industry often include [firm names]”
The LLM breaks the question into tokens, predicts the most likely answer based on patterns it learned during training, then fills in the firm names — but only firms whose content made those patterns clear.
The expert gets an upgrade: a research assistant with a smartphone. Before answering, the assistant searches the web, pulls the top articles, and hands them over. The expert reads those passages, combines them with what they already know, and gives a synthesised answer with citations.
"I think Australia won, but I'm not 100% sure."
"Australia won 4-0 — here are the match reports."
AI searches Google or Bing using their APIs under the hood
It checks the top 5–10 results only — speed matters
It tries to extract clear, structured information
If your content is a mess, it gets skipped
"Oh yeah mate, so you go down the hall, well actually it's more of a corridor, and there's a door on the left but that's the linen cupboard..."
"Bathroom: second door on the left."
These common content patterns make your expertise invisible to AI.
“Our TMT practice leverages cross-jurisdictional expertise” — AI can't map this to what clients actually search for.
Essential text locked in PDFs, infographics, or images that AI tools simply can't read or index.
Bullet points without context. Key information scattered across dozens of pages instead of one clear source.
Content written for experts, not for the clients actually asking questions. No industry context or plain-language framing.
“Our market-leading antitrust team advises on all aspects of corporate and M&A issues across all sectors.”
“We help companies in the technology sector navigate antitrust issues. This includes advising on cartels, antitrust litigation, regulatory compliance, and investigations.”
LLMs don't "understand" meaning — they predict patterns. Just like Spotify recommends Glass Animals because millions of Tame Impala listeners also liked them. Not because Spotify understands psychedelic rock.
Why this matters: If your content uses weird phrasing, the AI can't predict that "facilitates strategic commercial outcomes" means "we do M&A deals."
AI will only cite what it can reliably retrieve, parse, and trust. That comes down to two fundamentals.
What you say, and how clearly you say it.
Whether the content is technically readable — by humans and machines.
Content determines whether you're worth citing.
Accessibility determines whether you're possible to cite.
Both have the same size, same practice areas — but very different outcomes in AI search.
General Counsel at a major tech company considering an acquisition. She's new to the market and doesn't know the key legal players. She opens ChatGPT to shortcut her research.
Jane researches on ChatGPT
Firm B is surfaced; Firm A is missing
Shortlist created without Firm A
Firm B wins the RFP
This isn't hypothetical. In-house counsel are already asking AI for recommendations. Procurement teams are using AI to build firm shortlists. The firms that act now will be found first.
Same terminology and structure across every page. Contradictions force the model to hedge or skip you entirely.
Named industries, jurisdictions, outcomes. Generic statements are hard to differentiate and rarely get cited.
Who, what, where, when, why — all on one page. Thin pages lead to partial answers or competitor citations.
One authoritative page per topic. Scattered duplicates create conflicting passages the model can't resolve.
Dated, updated, and current. Stale content loses trust — newer content becomes the dominant passage.
If a screen reader can't parse it, neither can an LLM.
Proper headings, lists, and landmarks help machines interpret each section.
Describing images gives AI indexable context it can't get from pixels.
Content that flows in DOM order, not just visual order. Reduces mis-parsing.
Properly tagged PDFs and readable tables are more likely to be extracted and reused.
A repeatable process that fits into normal marketing work.
These are guesses, not strategies.
“All you need to do is write in plain English”
“Add more FAQs”
“Put keywords in your headings”
Start with measurement. You can't fix what you can't measure. Audit your content, prioritise by impact, then restructure for AI discoverability.
Choose 3–5 priority practice areas. Agree one geography per page set. Start where revenue matters most.
Use a tool like Content Intelligence to automatically generate thousands of real questions your audiences are asking — across every topic, intent, and persona — then test your content against them at scale.
Quarterly refresh of top copy. Add proof points to bios. Create answer-first insight templates. Redirect duplicates.
Canonical naming system. Marketing owns clarity, practice leaders own accuracy, digital owns accessibility.
You can't validate by asking ChatGPT two questions. You need hundreds of tests across multiple models, repeatedly.
Manually testing is not realistic. A tool lets you scan, identify issues, prioritise fixes, and prove lift.
Four content pillars that make your expertise discoverable.
Plain-language explanations of each practice area, with dedicated, crawlable pages. No jargon, no ambiguity.
Rich partner and lawyer bios. AI engines love authoritative human profiles with named expertise and credentials.
FAQs and “what does this mean for me?” guides. Generative AI prefers answers over brochures.
Clean URL structure, schema markup (especially for legal services), and updated sitemaps.
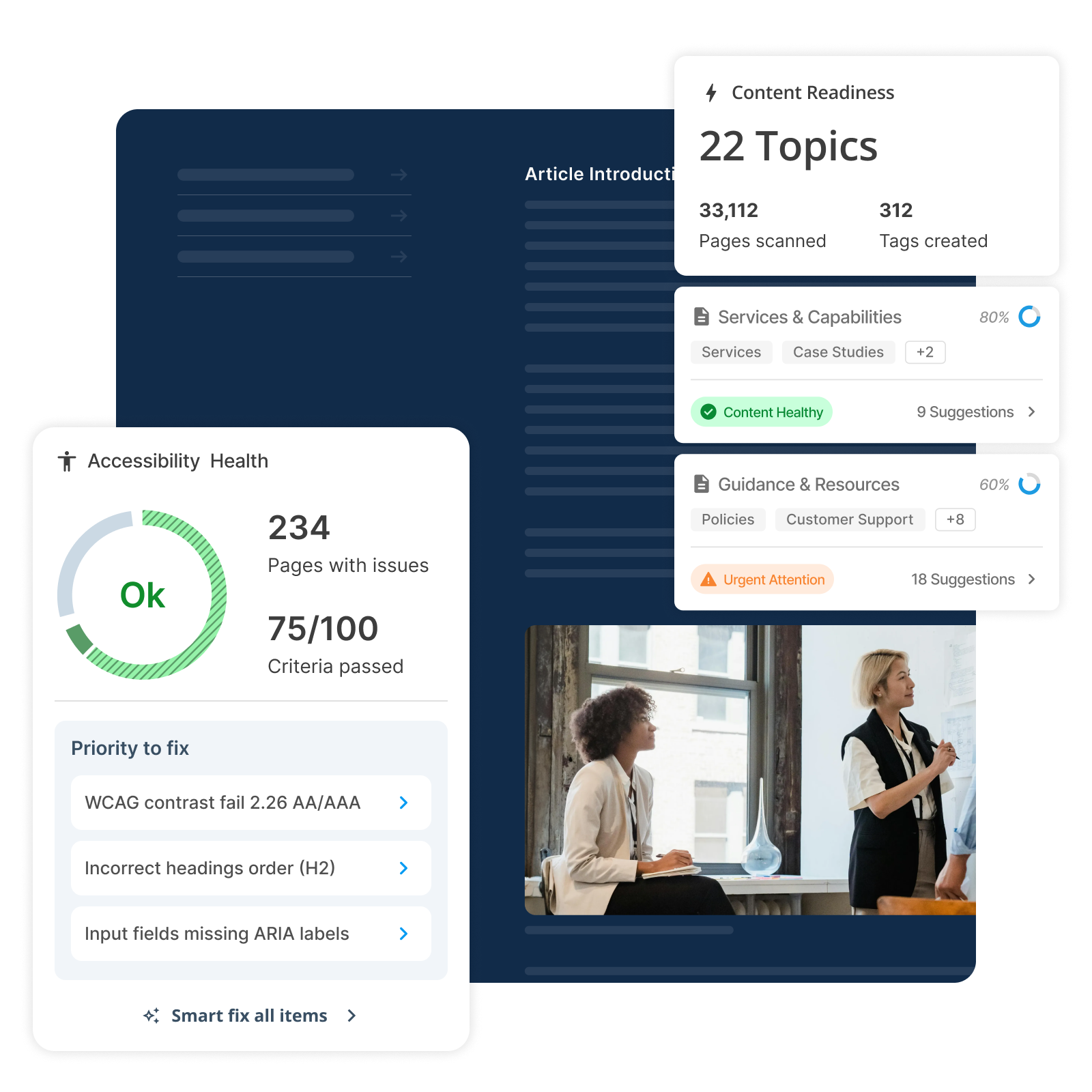
Make your content discoverable for AI Search. The diagnostic layer that tells you what to fix first.
Audit content structure for AI readability and discoverability.
Scan against WCAG 2.2 AA/AAA standards automatically.
Data-driven recommendations ranked by impact.
Compatible with all written web content. No migration required.
Watch an overview of how Content Intelligence helps you measure and improve AI discoverability.
See exactly how AI search platforms read your content today — and what to fix first.
Loading form…
Learn more about Content Intelligence

See your AI readiness at a glance